Utiliser l'application et query_plots()
using-query-plots-fr.RmdVue d’ensemble
CafriplotsR offre deux approches complémentaires pour accéder aux données de parcelles forestières :
-
Application Shiny interactive
(
launch_query_plots_app()) — interface pointer-cliquer avec carte en direct, sélection de parcelles et téléchargement -
Fonction R (
query_plots()) — accès reproductible et scriptable pour les flux de travail automatisés
Le panneau “Code R équivalent” de l’application fait
le lien entre les deux : il affiche l’appel exact à
query_plots() qui reproduit ce que vous avez configuré de
manière interactive.
Partie 1 — Application Shiny Interactive
Lancement de l’Application
# Lancer avec la langue par défaut (français)
launch_query_plots_app()
# Lancer en anglais
launch_query_plots_app(language = "en")
# Lancer dans le navigateur sur un port spécifique
launch_query_plots_app(language = "fr", launch.browser = TRUE, port = 8080)
# Réutiliser un pool de connexion existant (évite les invites répétées)
pool <- create_pool_main()
launch_query_plots_app(pool_main = pool)L’application demandera les identifiants de connexion si aucun pool
n’est fourni. Utilisez setup_db_credentials() pour stocker
les identifiants dans ~/.Renviron et éviter cette étape
lors des sessions futures.
Vue d’Ensemble de l’Application
L’application dispose de quatre onglets accessibles depuis la barre de navigation supérieure :
| Onglet | Rôle |
|---|---|
| Constructeur de requête | Définir les filtres et exécuter la requête de métadonnées |
| Résultats & Extraction | Carte, tableau, sélection de parcelles, configuration de l’extraction, téléchargement |
| Statistiques | Statistiques synthétiques et graphiques pour les données extraites |
| À propos | Documentation de l’application et informations sur le package |
Le sélecteur de langue (EN / FR) est toujours visible dans le coin supérieur droit. Le changement est instantané et affecte tous les éléments de l’interface.
Capture d’écran à ajouter : vue complète de l’application après la connexion, montrant la barre de navigation à quatre onglets (
app-query-nav-tabs-fr.png).
Onglet 1 — Constructeur de Requête
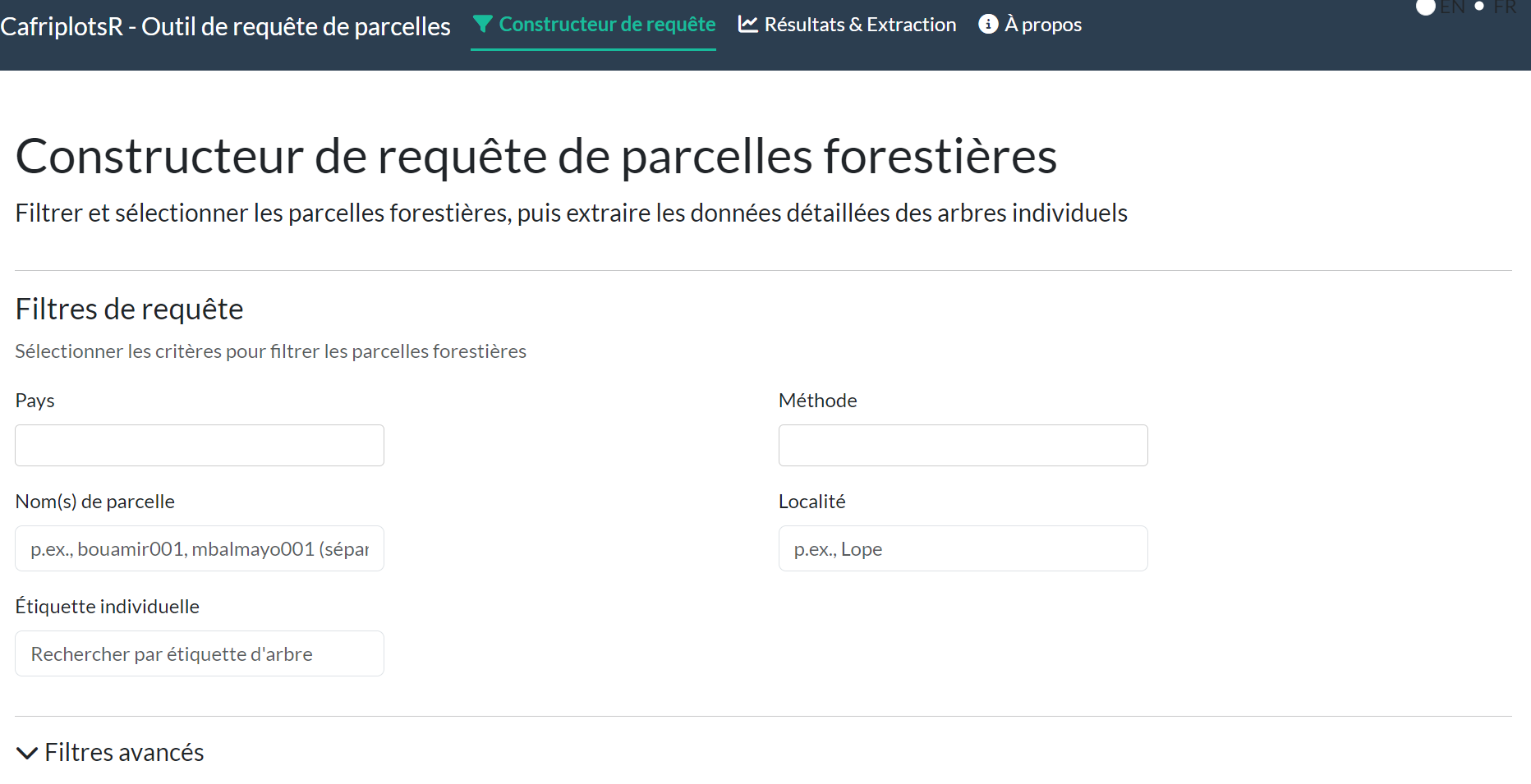
Filtres de Base
- Pays — menu déroulant multi-sélection des pays disponibles
- Méthode — méthode d’inventaire (ex. « 1 ha plot », « Long Transect »)
- Nom(s) de parcelle — recherche partielle ou exacte ; séparer plusieurs noms par des virgules
- Localité — recherche par nom de localité
- Étiquette individuelle — recherche par numéro d’étiquette d’arbre
Filtres Avancés
Cliquez sur Filtres avancés pour développer les options supplémentaires :
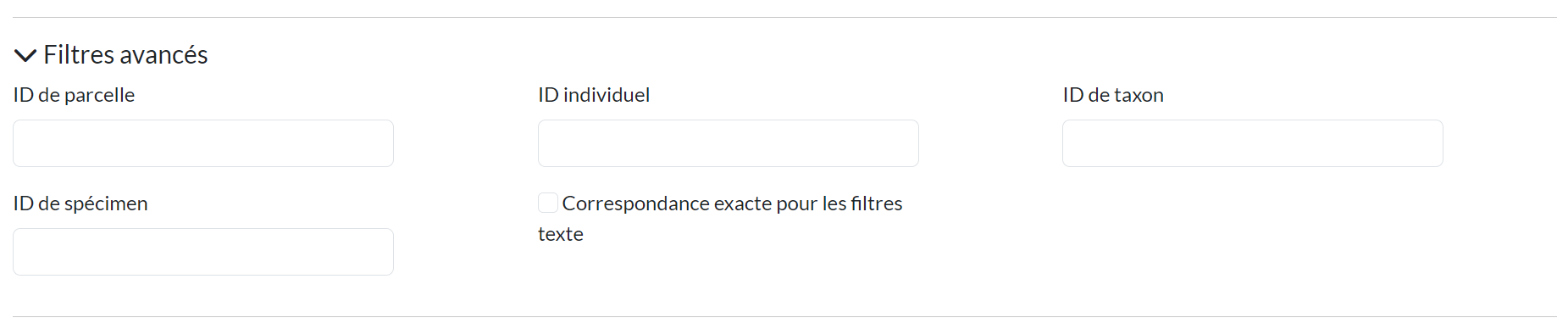
- ID de parcelle — recherche par ID interne de parcelle
- ID individuel — recherche par ID d’individu spécifique
- ID de taxon — filtrer par ID taxonomique
- ID de spécimen — recherche par ID de spécimen d’herbier
- Correspondance exacte — basculer pour une correspondance stricte (par défaut : partielle)
Onglet 2 — Résultats & Extraction
Cet onglet comporte cinq sections empilées qui vous guident de la visualisation des résultats jusqu’au téléchargement des données.
Section A — Carte Interactive
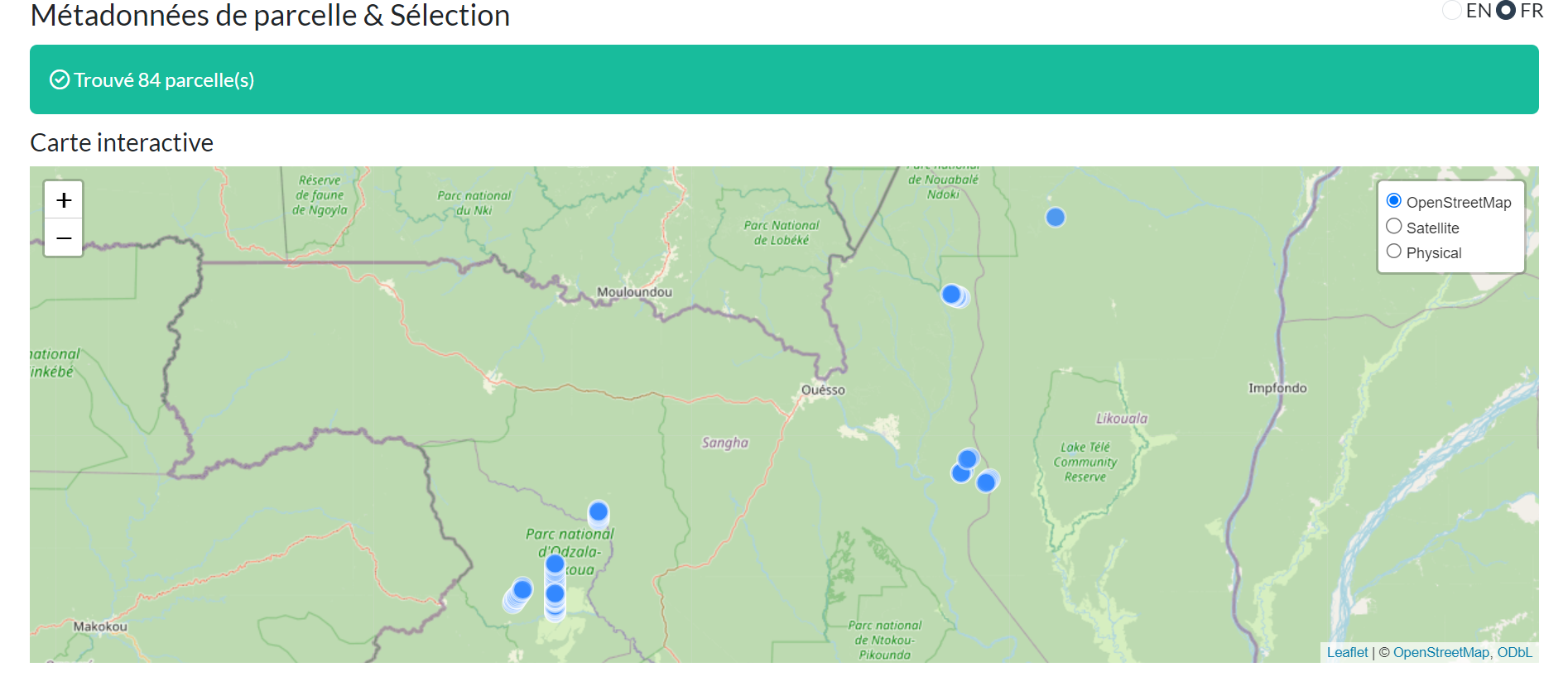
- Fonds de carte — OpenStreetMap, Satellite, Physique
- Marqueurs cliquables — affichent le nom de la parcelle, le pays, la méthode et la superficie
- La carte et le tableau sont synchronisés : sélectionner des lignes dans le tableau met en évidence les marqueurs correspondants
Section B — Tableau des Métadonnées
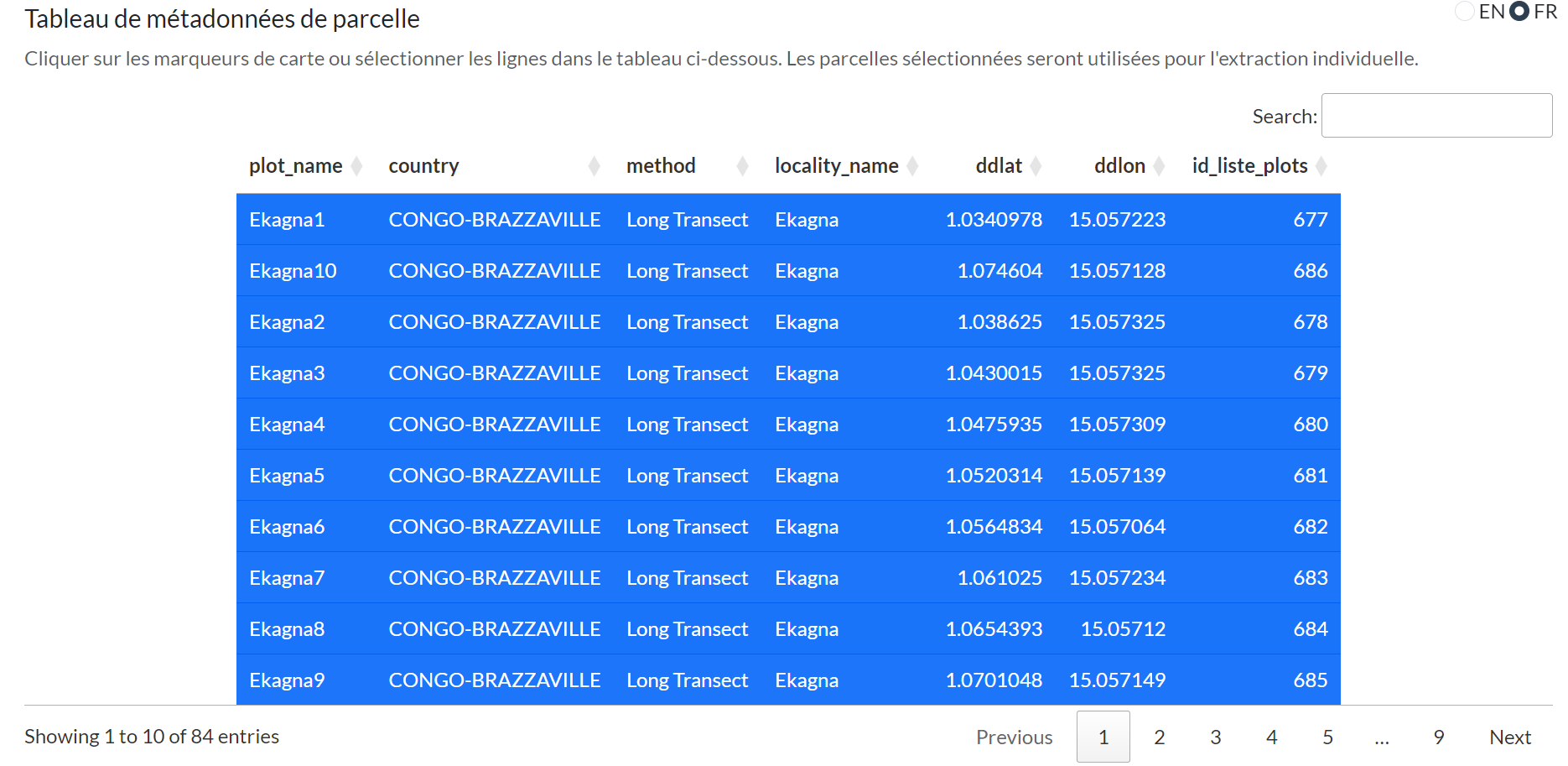
Un tableau DT triable et consultable de toutes les métadonnées de parcelles retournées par la requête. Cliquez sur les en-têtes de colonnes pour trier ; utilisez la zone de recherche pour filtrer les lignes.
Section C — Sélection des Parcelles
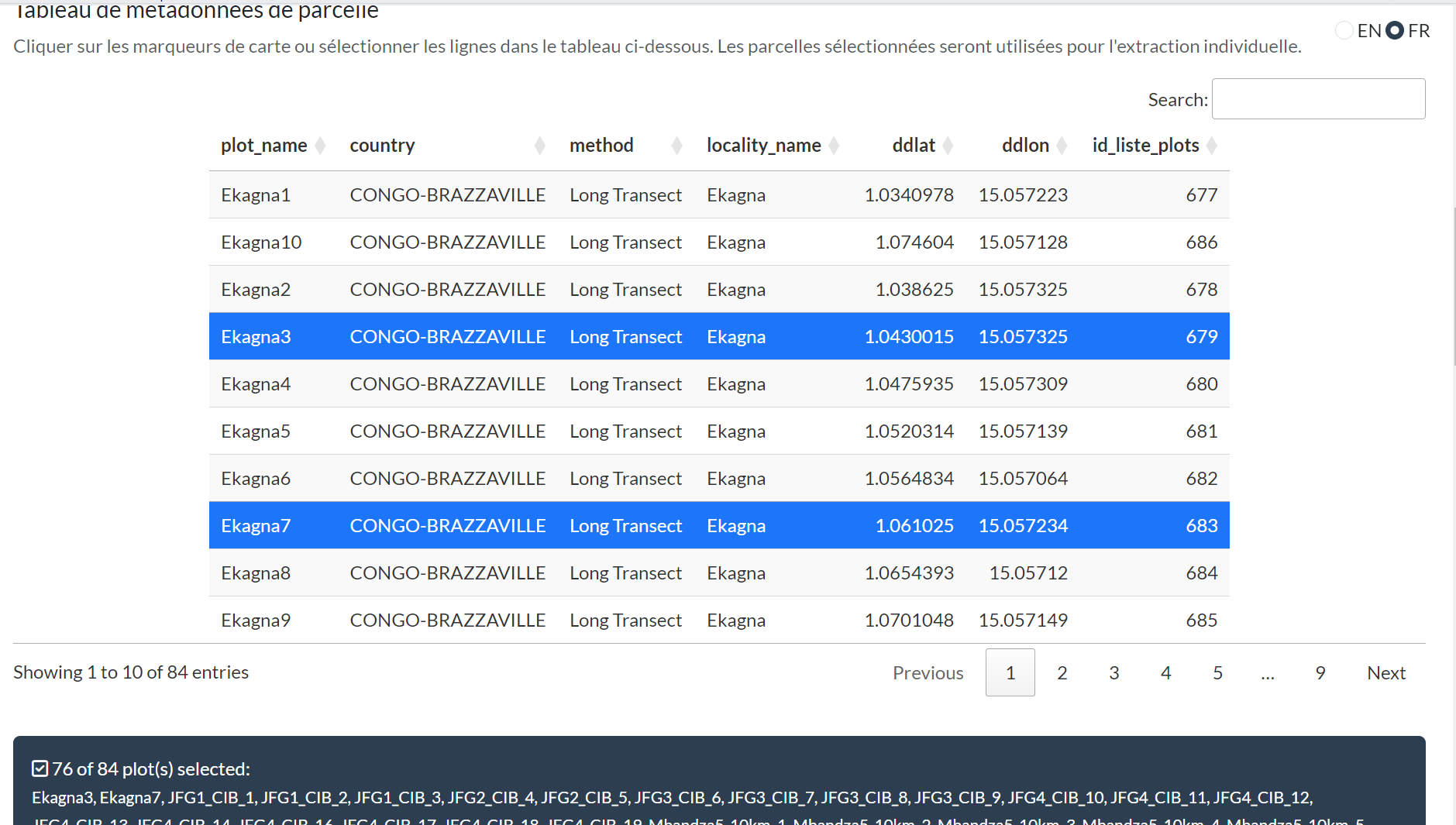
Cliquez sur les lignes pour sélectionner ou désélectionner des parcelles. Un compteur affiche le nombre de parcelles sélectionnées. Toutes les parcelles sont pré-sélectionnées par défaut.
Section D — Configuration de l’Extraction
Après avoir sélectionné les parcelles, configurez comment les données individuelles d’arbres doivent être extraites :
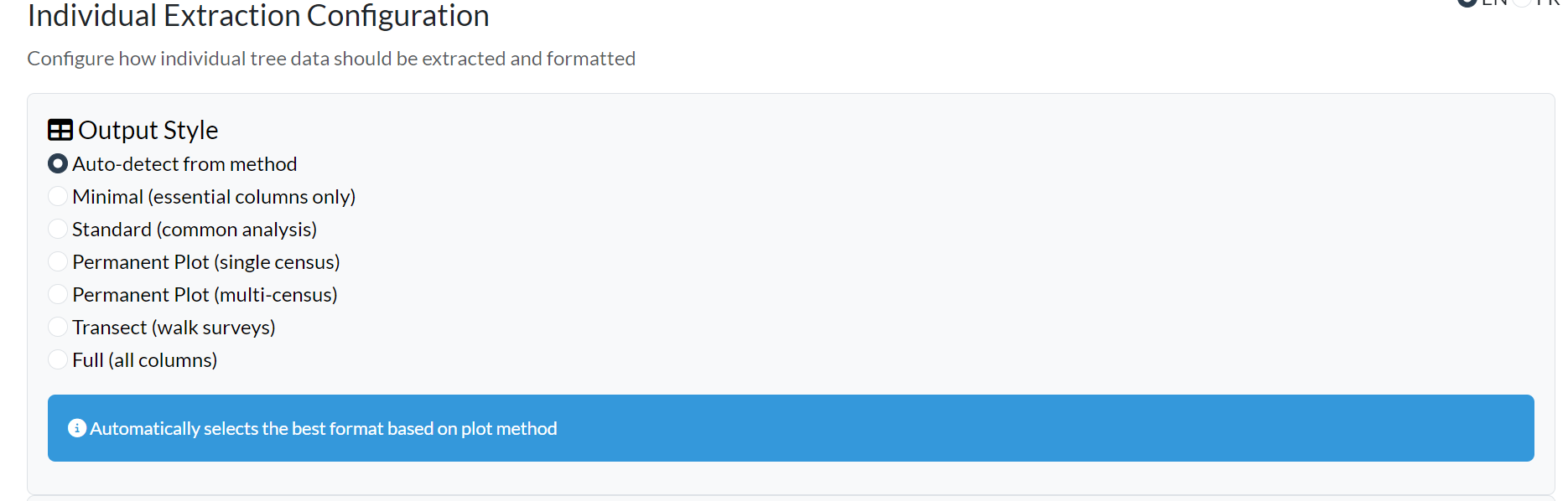
Style de sortie — contrôle les colonnes et les tables retournées :
| Style | Idéal pour |
|---|---|
| Détection automatique | Laisser l’application choisir selon la méthode de parcelle |
| Minimal | Exploration rapide — colonnes essentielles uniquement |
| Standard | Analyse écologique générale |
| Parcelle permanente | Suivi de parcelles permanentes à recensement unique |
| Parcelle permanente (multi-recensements) | Format séries temporelles avec colonnes _census_N
|
| Transect | Format relevé pédestre |
| Complet | Ensemble de données complet, toutes les colonnes |
Gestion des recensements :

- Stratégie de recensement — Dernier (par défaut), Premier, ou Moyenne entre tous les recensements
-
Afficher les données multi-recensements — crée des
colonnes
dbh_census_1,dbh_census_2, … ; sélectionne automatiquement le style Parcelle permanente (multi-recensements) -
Format des données individuelles :
- Large (par défaut) — une ligne par individu, traits en colonnes ; valeurs agrégées lorsque plusieurs mesures existent pour un même individu
-
Long — une ligne par mesure ; inclut les colonnes
trait,traitvalue,census_nameetcensus_date - Paires de recensements — une ligne par paire consécutive de recensements par individu ; utile pour calculer les taux de croissance
Organisation des données :
- Concaténer les tiges multiples — combiner les mesures des arbres à tiges multiples
- Supprimer les IDs de base de données — masquer les colonnes d’ID internes pour une sortie plus lisible
- Gestion des problèmes — supprimer, inclure ou ignorer les enregistrements signalés
- Inclure les drapeaux de problèmes — ajouter des colonnes de drapeaux de qualité à la sortie
Note : les formats Long et Paires de recensements sont incompatibles avec Concaténer les tiges multiples ; cette option est automatiquement désactivée lorsqu’un de ces modes est sélectionné.
Données additionnelles :
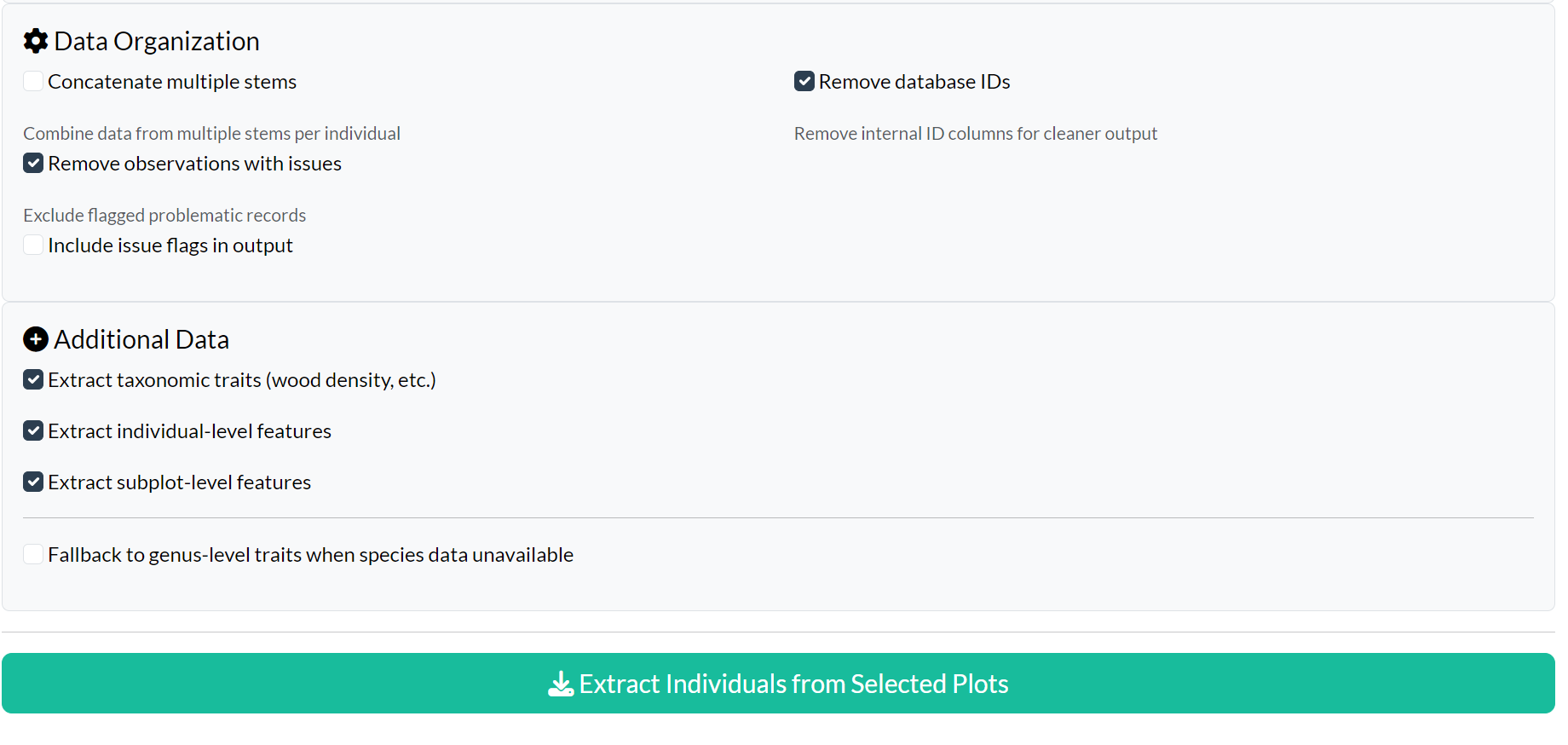
- Extraire les traits taxonomiques — densité du bois, forme de croissance, etc.
- Extraire les caractéristiques individuelles — mesures spécifiques aux arbres
- Extraire les caractéristiques de sous-parcelle — caractéristiques des sous-parcelles
- Utiliser les traits au niveau du genre — utiliser les données du genre lorsque les traits de l’espèce sont indisponibles
Cliquez sur Extraire les individus des parcelles sélectionnées pour lancer l’extraction.
Section E — Affichage des Résultats et Téléchargement
Les résultats sont organisés en onglets : Individus, Métadonnées, Recensements, Hauteur-Diamètre (si applicable), et Documentation des colonnes.
Capture d’écran à ajouter : affichage des résultats après extraction, montrant les onglets de résultats dont l’onglet Documentation des colonnes (
app-query-results-display.png).
L’onglet Documentation des colonnes est toujours présent après une extraction. Il contient un tableau consultable décrivant chaque colonne de sortie : son nom d’origine dans la base de données, une description en langage naturel, la catégorie, l’unité et des notes contextuelles. C’est le moyen le plus rapide de comprendre la signification de chaque colonne sans consulter une documentation externe.
Ce tableau est également exportable : cochez-le dans les options de téléchargement pour l’inclure en tant que feuille supplémentaire dans un export Excel, fichier CSV séparé dans l’archive ZIP, ou élément de la liste RDS.
Téléchargez vos données via le panneau de téléchargement :
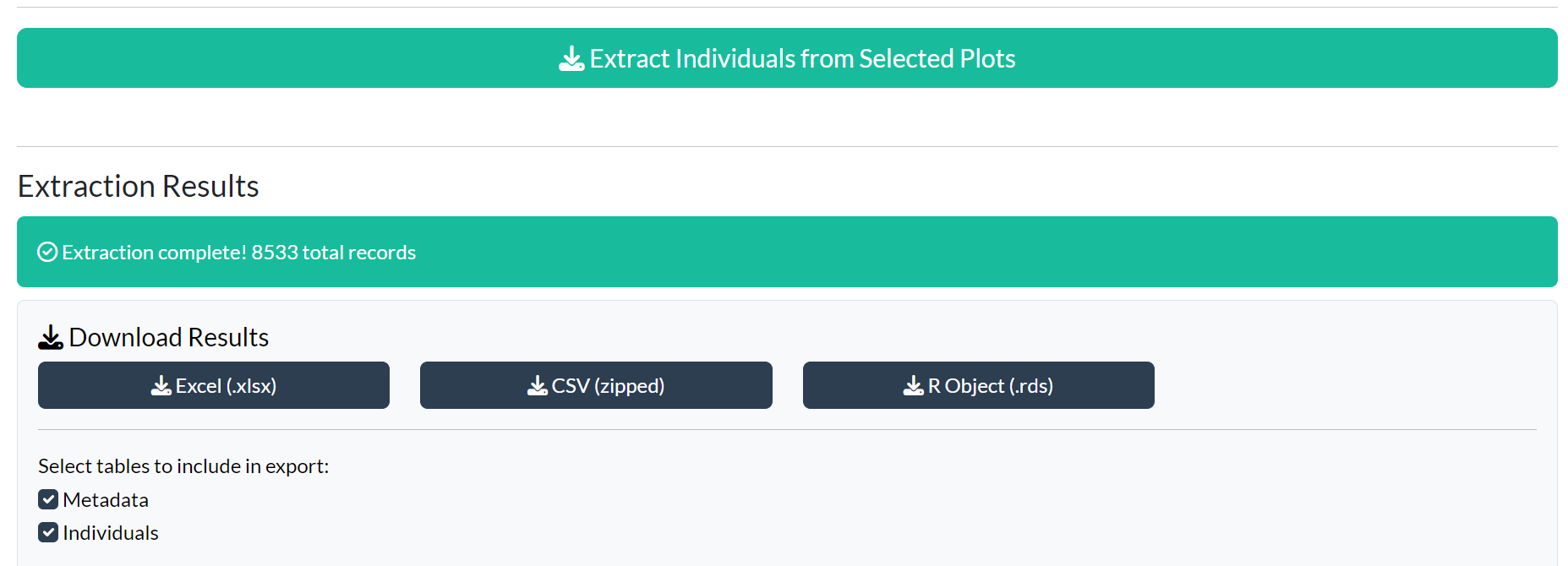
| Format | Notes |
|---|---|
| Excel (.xlsx) | Classeur multi-feuilles, une feuille par table |
| CSV (compressé) | Fichiers CSV séparés dans une archive ZIP |
| Objet R (.rds) | Format natif R ; préserve la structure de liste et les types de données |
| Shapefile (.zip) | Données spatiales (nécessite des colonnes de coordonnées) |
Utilisez les cases à cocher pour sélectionner les tables à inclure avant de télécharger.
Section F — Code R Équivalent
Après l’exécution d’une requête ou d’une extraction, le panneau
Code R équivalent affiche les appels exacts à
query_plots() qui reproduisent vos résultats :
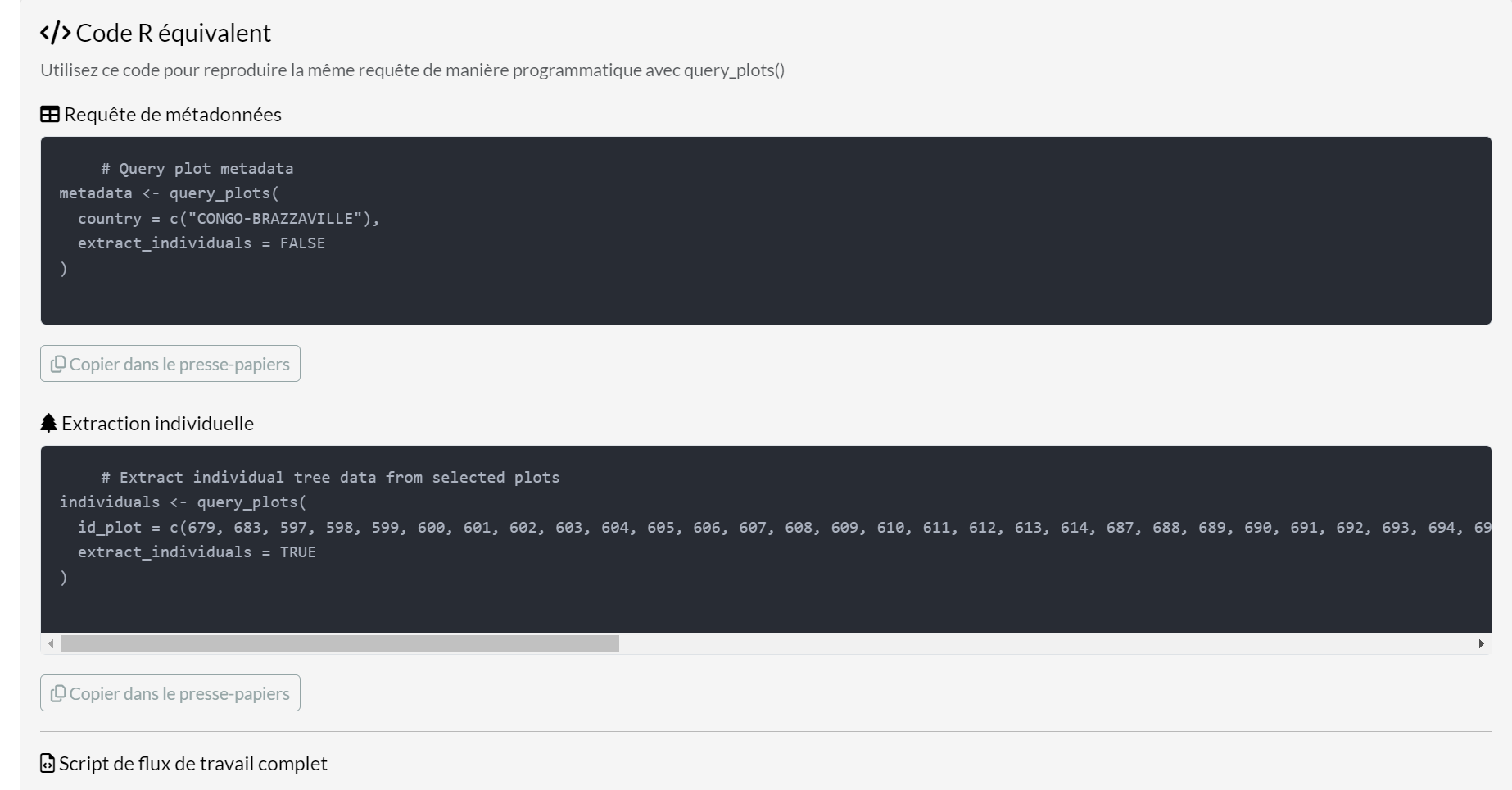
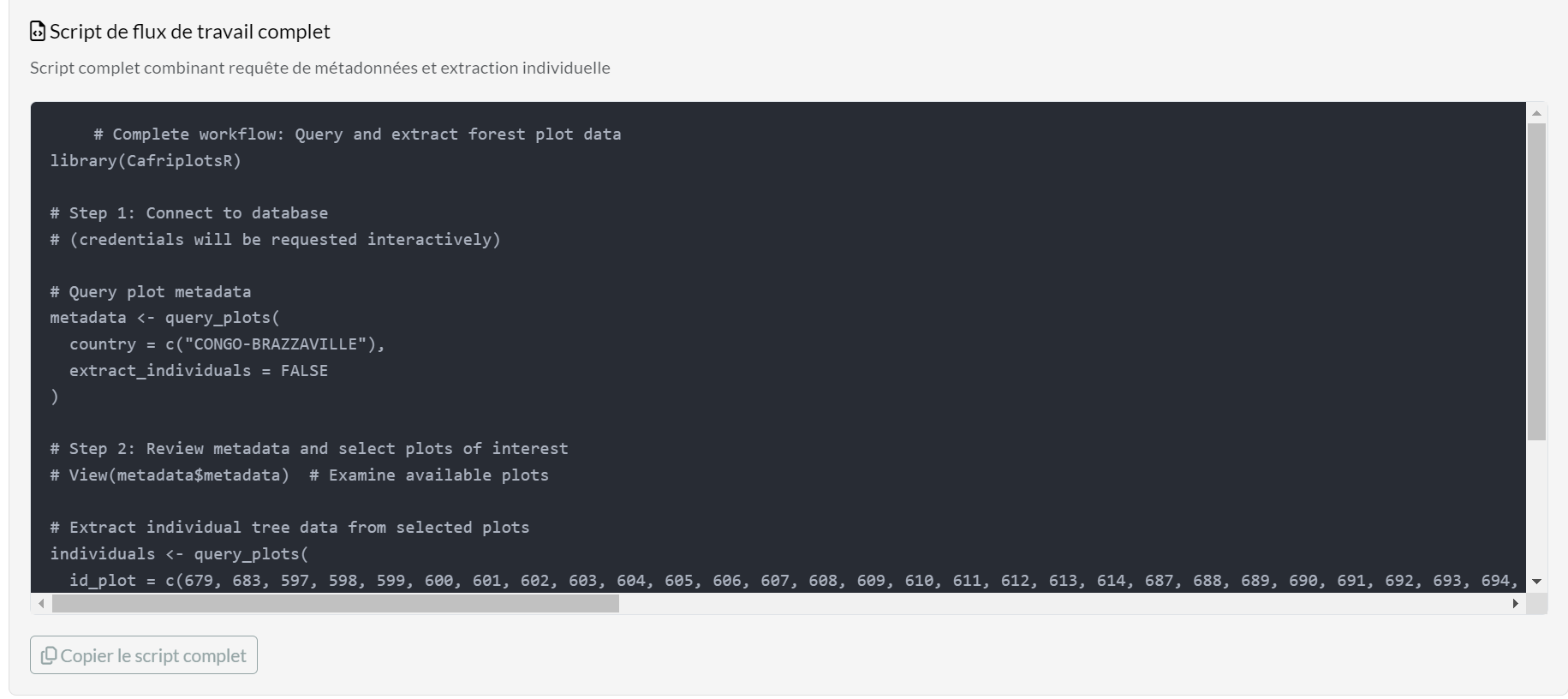
Trois sections de code sont disponibles :
- Requête de métadonnées — filtrer et récupérer les métadonnées de parcelles
- Extraction individuelle — extraire les données d’arbres avec les options choisies
- Script de flux de travail complet — les deux étapes dans un script prêt à l’emploi
Cliquez sur Copier dans le presse-papiers pour copier n’importe quelle section directement dans votre éditeur R.
Onglet 3 — Statistiques
L’onglet Statistiques affiche des cartes synthétiques et des graphiques mis à jour automatiquement dès que les données individuelles ont été extraites :
- Nombre total de parcelles extraites
- Nombre total d’individus (tiges)
- Nombre d’espèces
- Nombre de familles
- Histogramme de la distribution des diamètres (lorsque les données de DHP sont disponibles)
Capture d’écran à ajouter : onglet Statistiques montrant les quatre cartes synthétiques et l’histogramme de diamètres (
app-query-statistics.png).
Onglet 4 — À Propos
L’onglet À propos contient une description des fonctionnalités de l’application et les métadonnées du package (version, auteurs, liens vers la documentation et le dépôt).
Capture d’écran à mettre à jour : la page À propos affiche désormais la version 1.7.2 et la liste des auteurs mise à jour — refaire si votre capture existante date d’une version antérieure.
De l’Application au Script
Le flux de travail typique est :
- Utiliser l’application pour explorer les parcelles et configurer les options de manière interactive
- Copier le code généré depuis le panneau Code R équivalent
- Coller dans votre script d’analyse pour des exécutions reproductibles et automatisées
# Exemple de code généré par l'application après sélection de parcelles
# d'1 ha au Cameroun
# Étape 1 : requête de métadonnées
metadata <- query_plots(
country = "Cameroon",
method = "1 ha plot",
extract_individuals = FALSE
)
# Étape 2 : extraction des individus des parcelles sélectionnées
result <- query_plots(
id_plot = c(1, 5, 12),
extract_individuals = TRUE,
output_style = "permanent_plot",
extract_traits = TRUE,
census_strategy = "last"
)Application vs Fonction : Quand Utiliser Chacune
| Cas d’utilisation | Recommandation |
|---|---|
| Première exploration, IDs de parcelles inconnus | Application |
| Sélection interactive sur carte | Application |
| Apprentissage des paramètres de la fonction | Application — copier le code généré |
| Scripts d’analyse reproductibles | query_plots() |
| Pipelines de données automatisés | query_plots() |
| Traitement en masse de nombreuses requêtes | query_plots() |
Partie 2 — Fonction query_plots()
Connexion à la Base de Données
# Recommandé : invite interactive de saisie des identifiants
mydb <- call.mydb()
# Utiliser les identifiants stockés dans ~/.Renviron
mydb <- call.mydb(use_env_credentials = TRUE)La connexion à la base de données taxonomique est créée
automatiquement par query_plots() lorsqu’elle est
nécessaire. Fournissez-la explicitement via con.taxa pour
réutiliser une connexion existante et éviter les invites répétées :
mydb <- call.mydb()
mydb_taxa <- call.mydb.taxa()
result <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
con = mydb,
con.taxa = mydb_taxa
)Utilisation de Base
Métadonnées uniquement (sans données d’arbres)
plots <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = FALSE
)
plots$metadataAvec les arbres individuels
result <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE
)
names(result) # ex. metadata, individuals, censuses, height_diameter
result$individuals # une ligne par tige
result$censuses # dates de recensement et informations d'équipeStyles de Sortie
query_plots() retourne toujours une liste
nommée. Les tables incluses et les colonnes conservées
dépendent de output_style. Styles intégrés :
output_style |
Description | Tables additionnelles |
|---|---|---|
"auto" |
Détecté depuis la method de la parcelle (défaut) |
variable |
"minimal" |
Métadonnées essentielles uniquement | — |
"standard" |
Sortie générale pour analyse | — |
"permanent_plot" |
Suivi de parcelle permanente, recensement unique / le plus récent |
censuses, height_diameter
|
"permanent_plot_multi_census" |
Format multi-recensement large (colonnes
_census_N) |
censuses, height_diameter
|
"transect" |
Sortie simplifiée pour transects / relevés pédestres | — |
"census_pairs" |
Une ligne par paire de recensements consécutifs par individu | — |
"full" |
Conserve toutes les colonnes des tables metadata et individuals | — |
# Détection automatique depuis la méthode (recommandé)
result_auto <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE
)
# Forcer un style spécifique
result_perm <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
output_style = "permanent_plot"
)
# Le style "full" conserve toutes les colonnes des tables metadata et individuals
result_full <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
output_style = "full"
)
names(result_full$individuals)Inspecter les styles intégrés
Deux fonctions utilitaires permettent de découvrir le contenu de chaque style sans quitter R :
# Tableau récapitulatif de tous les styles intégrés
list_output_styles()
# Configuration complète d'un style, avec une méthode print() lisible
get_output_style("permanent_plot")
# Retirer la classe pour accéder aux champs programmatiquement
cfg <- unclass(get_output_style("permanent_plot"))
cfg$metadata_columns
cfg$remove_patternslist_output_styles() renvoie un tibble avec une ligne
par style et le nombre de colonnes explicites / motifs regex.
get_output_style() renvoie un objet
plot_output_style dont la méthode print
regroupe les champs par catégorie (sélection de colonnes, filtres regex,
renommages, tables additionnelles, indicateurs).
Styles de sortie personnalisés
Si aucun style intégré ne convient, construisez le vôtre avec
output_style() et passez l’objet résultant directement à
query_plots() :
mon_style <- output_style(
description = "IDs et espèces uniquement",
metadata_columns = c("plot_name", "country", "id_liste_plots"),
individuals_columns = c("id_n", "tag", "tax_fam", "tax_gen", "tax_sp_level")
)
result <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
output_style = mon_style
)Utilisez based_on pour partir d’un style existant et
n’écraser que les champs souhaités. La sémantique est «
remplacer, pas ajouter » : tout champ fourni remplace
entièrement la valeur du parent. Pour effacer un champ vectoriel tout en
héritant du reste, passez un vecteur vide
(remove_patterns = character()) ; pour hériter sans
modification, ne spécifiez pas l’argument.
# Partir de permanent_plot, mais supprimer toutes les colonnes trait_*
perm_no_traits <- output_style(
based_on = "permanent_plot",
remove_patterns = c(
"^id_(?!n|liste_plots)", "^date_modif",
"_census_\\d+$", "^trait_"
)
)
perm_no_traits # affichage formaté
result <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
output_style = perm_no_traits
)Les objets de style personnalisé n’existent que dans la session R
courante. Pour les réutiliser, assignez-les à une variable,
sauvegardez-les avec saveRDS(), ou placez l’appel
constructeur dans votre .Rprofile ou dans un script de
projet.
keep_patterns et remove_patterns
Au-delà des listes explicites metadata_columns /
individuals_columns, chaque style accepte deux filtres
regex appliqués en plus de la sélection de colonnes :
-
keep_patterns— expressions régulières compatibles Perl. Toute colonne dont le nom correspond à au moins un motif est ajoutée à la liste des colonnes conservées (utile pour récupérer des familles entières de colonnes, par ex.^feat_ouwood_density). -
remove_patterns— appliqués aprèskeep_patternspour supprimer des colonnes. Souvent utilisés pour retirer les identifiants internes ("^id_(?!n|liste_plots)"), les horodatages de modification ("^date_modif") ou les colonnes par recensement ("_census_\\d+$").
# Conserver toutes les colonnes wood_density et stem_diameter,
# supprimer les IDs internes
mon_style <- output_style(
based_on = "standard",
keep_patterns = c("wood_density", "stem_diameter"),
remove_patterns = c("^id_(?!n|liste_plots)", "^date_modif")
)Options de Filtrage
# Par pays
query_plots(country = "Cameroon", extract_individuals = FALSE)
# Par méthode
query_plots(method = "1 ha plot", extract_individuals = FALSE)
# Plusieurs pays ou méthodes
query_plots(country = c("Cameroon", "Gabon"), extract_individuals = FALSE)
# Par localité
query_plots(locality_name = "Dja", extract_individuals = FALSE)
# Par ID de parcelle (le plus efficace lorsque les IDs sont connus)
query_plots(id_plot = c(1, 2, 3), extract_individuals = TRUE)
# Par étiquette individuelle (implique extract_individuals = TRUE)
query_plots(plot_name = "mbalmayo001", tag = "1234")
# Par ID de taxon
query_plots(plot_name = "mbalmayo001", id_tax = 115, extract_individuals = TRUE)
# Par ID de spécimen d'herbier
query_plots(id_specimen = 42, extract_individuals = TRUE)
# Correspondance exacte du nom de parcelle (partielle par défaut)
query_plots(plot_name = "mbalmayo001", exact_match = TRUE, extract_individuals = FALSE)Gestion des Recensements Multiples
# Dernier recensement uniquement (par défaut)
dernier <- query_plots(
plot_name = "mbalmayo",
extract_individuals = TRUE,
census_strategy = "last"
)
# Premier recensement
premier <- query_plots(
plot_name = "mbalmayo",
extract_individuals = TRUE,
census_strategy = "first"
)
# Valeurs moyennes sur tous les recensements
moyenne <- query_plots(
plot_name = "mbalmayo",
extract_individuals = TRUE,
census_strategy = "mean"
)
# Tous les recensements en colonnes séparées (dbh_census_1, dbh_census_2, …)
multi <- query_plots(
plot_name = "mbalmayo",
extract_individuals = TRUE,
show_multiple_census = TRUE # bascule automatiquement sur le style multi-recensement
)
multi$censuses # dates de recensement
head(multi$individuals)Format des Données Individuelles
Trois structures de lignes sont disponibles :
# Large (par défaut) : une ligne par individu, traits en colonnes
large <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
individual_features_format = "wide"
)
# Long : une ligne par mesure
long <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
individual_features_format = "long"
)
# Colonnes supplémentaires : trait, traitvalue, traitvalue_char, valuetype,
# census_name, census_date
long$individuals |>
dplyr::select(plot_name, tag, tax_sp_level, trait, traitvalue, census_name, census_date)
# Paires de recensements : une ligne par paire consécutive de recensements
# Utile pour calculer la croissance en diamètre entre recensements
paires <- query_plots(
plot_name = "mbalmayo",
extract_individuals = TRUE,
individual_features_format = "census_pairs"
)
# Le style de sortie est automatiquement réglé sur "census_pairs"Référentiel Taxonomique
# Taxonomie interne (par défaut)
result_interne <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
backbone = "internal"
)
# WCVP (World Checklist of Vascular Plants)
result_wcvp <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
backbone = "wcvp"
)Options de Données Additionnelles
result <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
extract_traits = TRUE, # traits taxonomiques (densité du bois, forme de croissance…)
extract_individual_features = TRUE, # mesures au niveau de l'arbre
extract_subplot_features = TRUE, # caractéristiques de sous-parcelle
traits_to_genera = FALSE, # utiliser le genre si les traits de l'espèce sont absents
wd_fam_level = FALSE, # utiliser la densité du bois au niveau de la famille
include_liana = FALSE # mettre TRUE pour conserver les lianes dans la sortie
)Données Spatiales
# Par défaut : une coordonnée représentative par parcelle
plots <- query_plots(country = "Gabon", extract_individuals = FALSE)
plots$metadata[, c("plot_name", "latitude", "longitude")]
# Tous les points de coordonnées (coins, centres de sous-parcelles…)
tous_coords <- query_plots(
plot_name = "mbalmayo",
extract_individuals = FALSE,
extract_coordinates = TRUE # remplace le paramètre déprécié show_all_coordinates
)
tous_coords$coordinates_sf # objet sfNote :
show_all_coordinatesa été déprécié en v1.9.4. Utilisezextract_coordinatesà la place.
# Afficher une carte Leaflet interactive (s'ouvre dans le visualiseur RStudio)
query_plots(country = "Cameroon", extract_individuals = FALSE, map = TRUE)Conserver les IDs de Base de Données
result <- query_plots(
plot_name = "mbalmayo001",
extract_individuals = TRUE,
remove_ids = FALSE,
output_style = "full"
)
names(result$extract) # inclut id_liste_plots, id_census, id_n…Gestion des Problèmes de Qualité
# Supprimer les enregistrements signalés (par défaut)
propre <- query_plots(
plot_name = "mbalmayo001", extract_individuals = TRUE,
issues = "remove"
)
# Inclure tous les enregistrements quel que soit leur statut
tous <- query_plots(
plot_name = "mbalmayo001", extract_individuals = TRUE,
issues = "include"
)
# Conserver les enregistrements signalés avec des colonnes de drapeaux
avec_drapeaux <- query_plots(
plot_name = "mbalmayo001", extract_individuals = TRUE,
issues = "ignore"
)Exemple de Requête Complexe
result <- query_plots(
country = "Cameroon",
locality_name = "Dja",
method = "1 ha plot",
extract_individuals = TRUE,
extract_traits = TRUE,
extract_individual_features = TRUE,
show_multiple_census = TRUE,
extract_coordinates = TRUE,
remove_ids = FALSE,
output_style = "permanent_plot_multi_census"
)
names(result)Conseils de Performance
- Commencer par
extract_individuals = FALSEpour explorer les métadonnées avant de charger les données d’arbres - Filtrer par
id_plotlorsque les IDs sont déjà connus — c’est la route la plus efficace - N’activer
extract_traits = TRUEetextract_individual_features = TRUEque lorsque c’est nécessaire - Choisir le
output_stylele plus spécifique pour éviter de charger des colonnes inutiles
Dépannage
# Vérifier le statut de la connexion
print_connection_status()
# Exécuter un diagnostic complet de la connexion
db_diagnostic()
# Fermer toutes les connexions et effacer les identifiants en cache
cleanup_connections()La sécurité au niveau des lignes est appliquée sur la base de données : vous ne pouvez accéder qu’aux parcelles et aux individus pour lesquels votre compte de base de données dispose des permissions nécessaires.